Table of Contents
Proposal
Results
Final Project for MUSA 550 Geospatial Data Science in Python.
A Look at Reddit’s Values, IRL Events, and Possible Bad Actors
Gianluca Mangiapane, Bri Cervantes
Question We Set Out to Answer, and the Answer We Found
1. What does Reddit Value? What are the common characteristics/patterns in top r/all posts?
Given Reddit’s self-defined culture, we wanted to first investigate what users on Reddit value. While we know that Reddit is home to countless sub-cultures, our approach focused on indentifying the overarching culutre of Reddit. What becomes the most popular? R/all is the front page of Reddit and is where all the most popular posts end up. It collects posts from subreddits across that platform that agree to participate and represents the majority rule of Reddit.
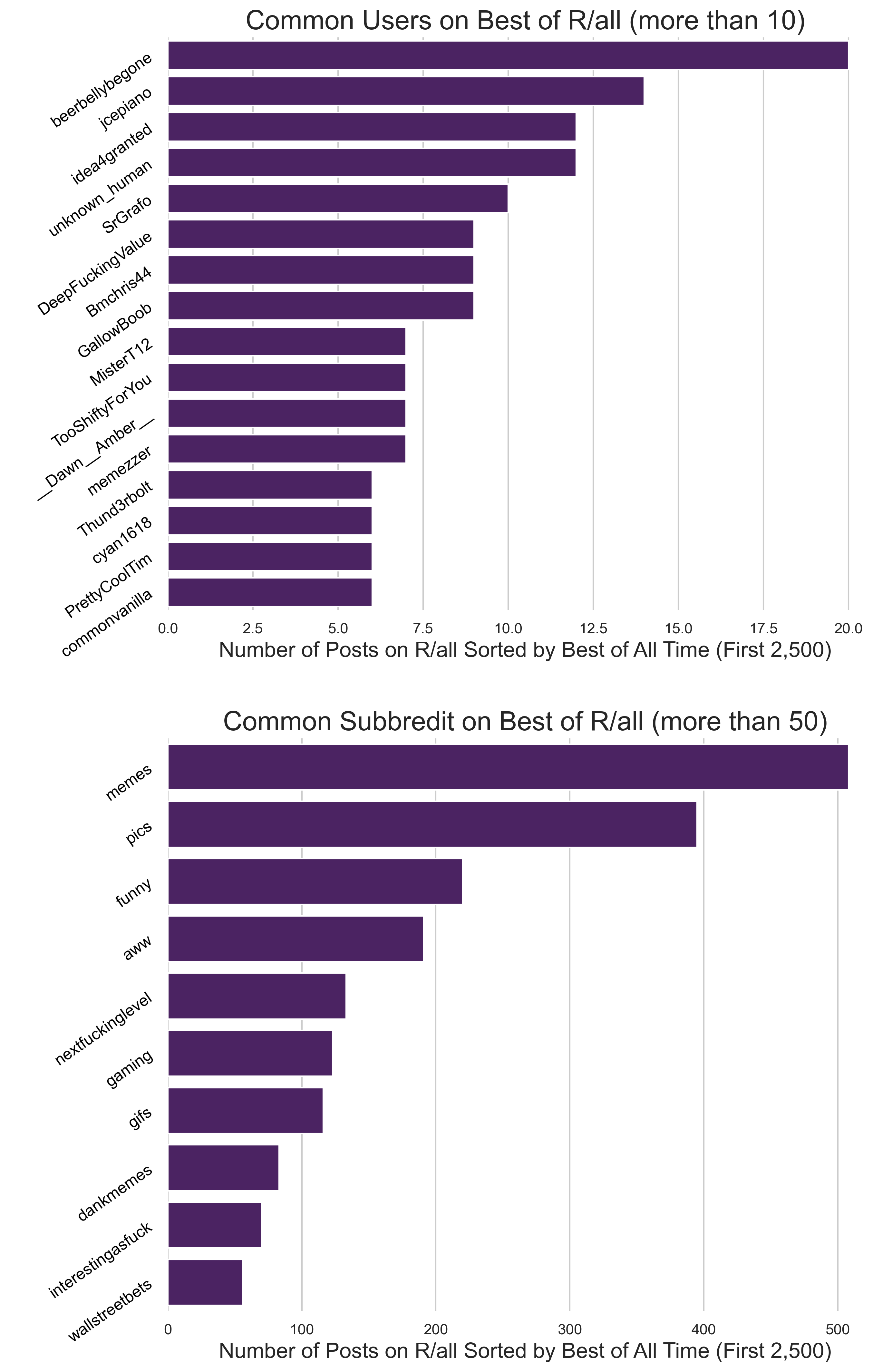
In seeking to find out more about what gets popular, we pulled roughly 2,500 top posts from r/all sorted by best of all time. We wanted to know if popular posts were positive or negative, whose posts were becoming popular and by extension if there were a small group of people that dominate the r/all space? Similarly, we were interested in where the popular posts were coming from: were there a small group of subreddits that dominate r/all? Further, we attempted to identify common themes between the posts.
We first took a look at possible superusers; users with posts that ended up in our sample of r/all posts more than 10 times, and super-subreddits; subreddits where more than 50 posts in our sample originated from. There were plenty in both categories. We should note that at least one the users on the top graph is u/DeepF*ckingValue, the claimed leader of the wallstreet takeover by reddit users on r/WallStreetBets.
Next, we investigated the general sentiment of these posts and associated them with the subreddits they came from. To do so we used TextBlob, which provided polarity and subjectivity ratings. When we noticed some odd results we experimented with another NLP, Flair. Below are the results showing polarity ratings from Flair and Textblob, as well as Textblob’s sentiment ratings. The graph below shows the sentiment for all of the posts we pulled from r/all grouped by the subreddit they came from. (Click on the image to open it in a new tab and zoom in.)
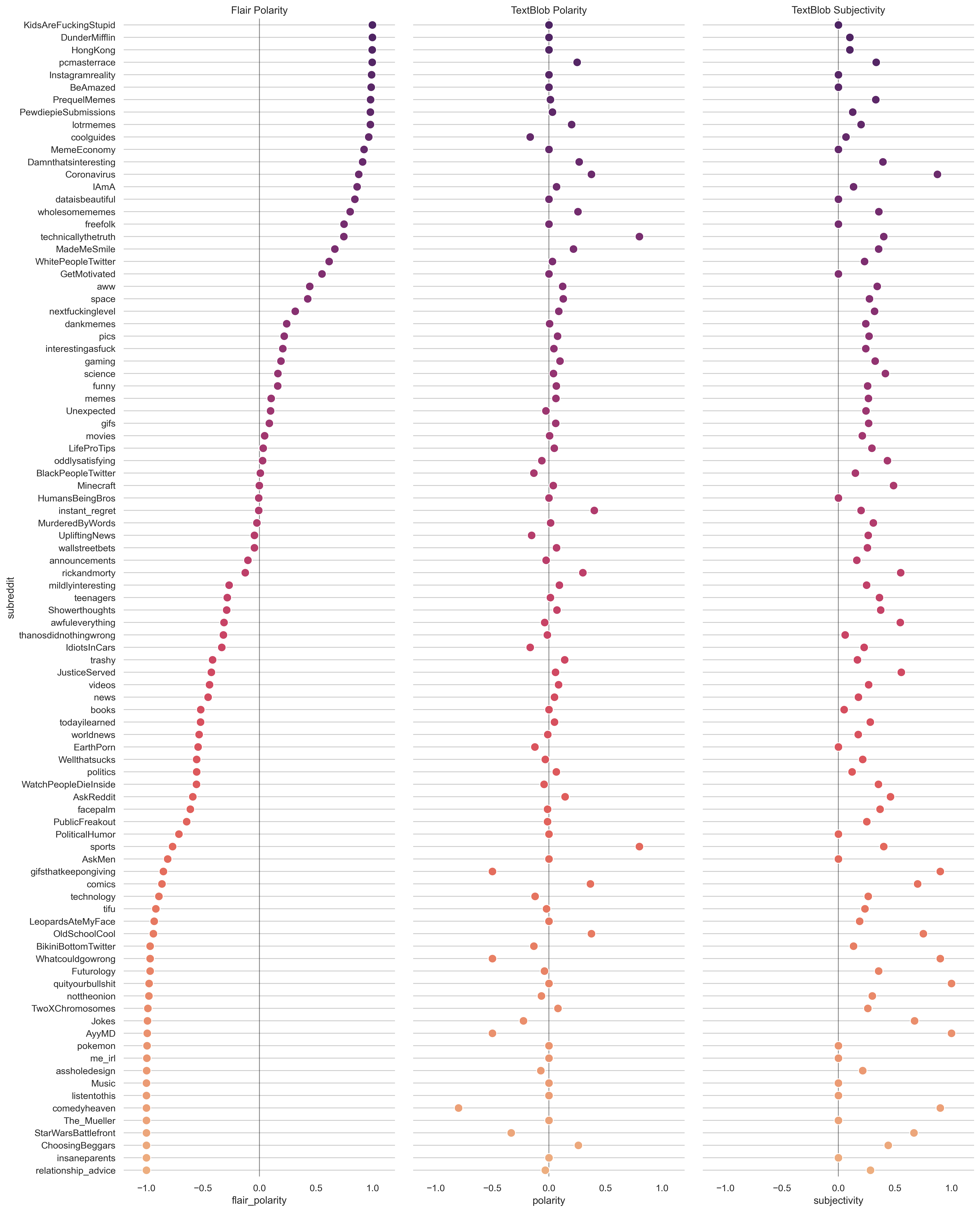
It’s clear even by the name of some subreddits what the polarity rating might be. For example, r/wholesomemes trends positive under Textblob and Flair polarity ratings, while r/wellthatsucks was rated very negative by Flair and only slightly negative by Textblob. Another way to examine general polarity of the posts we captured is to inspect the most frequent noun phrases. The interactive plot below shows a list of the top 100 most common noun phrases mapped with their polarity determined by Flair on the left.
Finally, we attempted to identify some common themes in the posts that we pulled from r/all. Using the Gensim library we employed a topic model to extract common themes in the noun phrases extracted from the titles by again using Textblob. With the help of examples published by Data Science With Raghav we identified roughly 20 clusters of potential themes. Below is a preview of an interactive chart that shows the top 10 words in each topic cluster on the right. (Click here or on the image below to visit the interactive chart) On the left, is a intertopic distance map, that in very simple terms shows the relative ‘distance’ between the topics identified. Circles that are closer together represent topics that are more related to each other than circles far apart. Additionally the size of the cirlces represent the number of words associated with each topic. Though we’ve elected to only show the top 10 wordsc, some topics include over 30 keywords.
This visualization was first developed by Carson Sievert and Kenneth E. Shirley., and more details about how to interpret it can be found on alteryx.com.
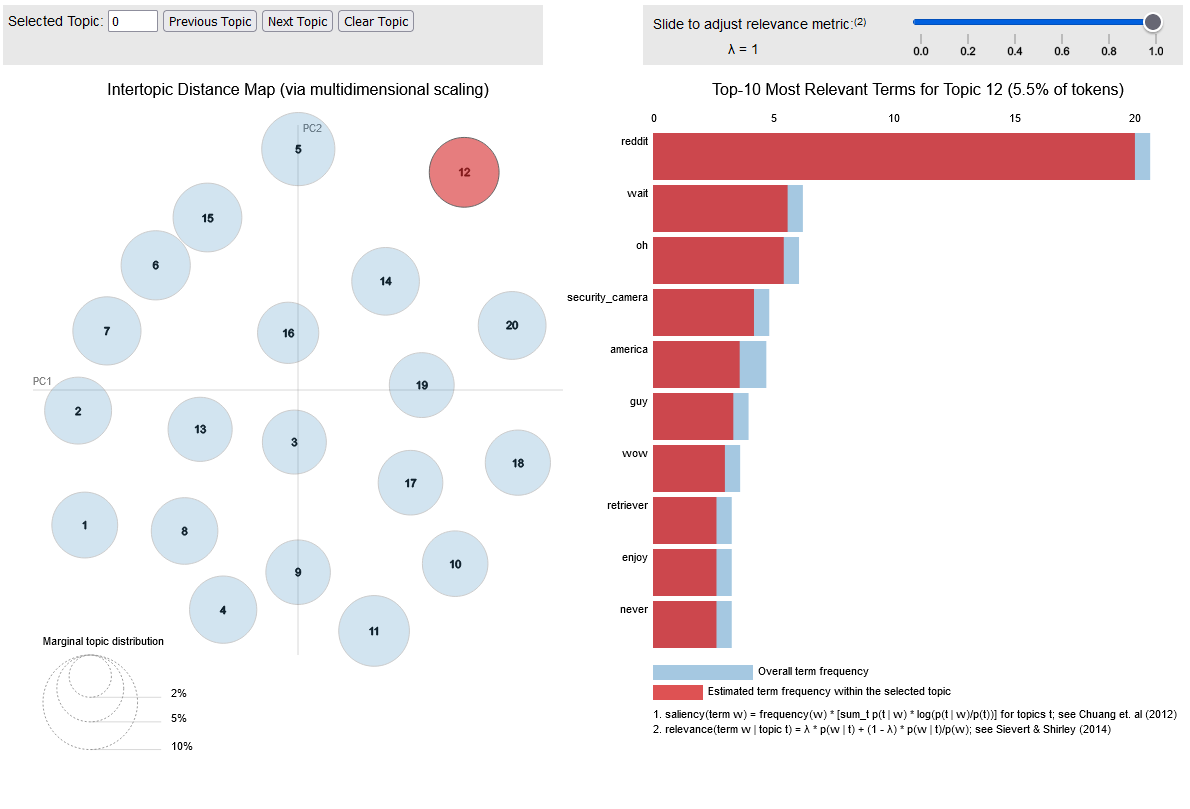
If you find this chart confusing, you’re not alone. We believe that the visual representation is very clear, but what exactly the topics are is not. Further we believe that this is a result of the data and the nature of Reddit. As shown in the bar graphs of common subreddits featured on r/all, the top two most common subreddits are r/pics and r/memes. These are two image based subreddits and, from our experience as reddit users, we can assume that the titles associated with image posts may not be all that illuminating of what the context of the post is. Additionally, Reddit is a very weird place, where platform-wide inside jokes abound. While our knowledge of natural language processing is limited, we think it’s safe to say that the LDA model we employed could not have been expected to pick up on the nuances of Reddit’s jokes. Without clear insight into the themes that are most likely to get popular on Reddit, we turn to what we see as the only likely commonality between posts: current events.
2. How representative is Reddit’s front page of what’s happening in the world?
While Reddit is a subculture unto itself (ex.1, ex.2), it’s not possible for the platform to fully extricate itself from the rest of the IRL world. As a result, its lively subculture not only amplifies reddit-wide values, but it can also act as an accelerant for ideas and narratives that have context outside of Reddit. Further, the loyalty that users have to the site might mean they use it for more than just fun. In 2016, the Pew Research Center found that 78% of Reddit users get their news from the site.1
{kind=link}
To continue in our attempt to decode what makes a popular post on Reddit, we sought to compare topic themes between a subset of recent posts pulled from r/all, sorted by hot and current news headlines. Using the same technique of LDA topic modelling we extracted a number of themes from r/all posts and newsheadlines from english news sources. Then we used difflib’s SequenceMatcher to identify any overlapping themes. According to SequenceMatcher’s documentation, a score of 0.6 or higher can be interpreted as a reasonable match. Comparing lists of the top 10 noun phrases associated with 15 and 20 topics for r/all and the news sources, respectively we found zero matches.
We’re not sure why this was our result. There is of course a possibility that our lack of expertise with topic modelling played a role. However, we think it’s also worth considering the interpretation that our results are not a sign that there is no topic overlap in our samples, but rather that the overlap is difficult to identify. This may be true for reason stated above - the fact the most common subreddits to be featured on r/all are image based (r/memes and r/images). Or it may be due to the truncated nature of titles on reddit posts. To be fair, we did not look at the text body of posts, but we made that decision based on our knowledge as users that a great deal of posts are image based.
Beyond identifying shared topics between r/all and news headlines, we were also interested in investigated whether news sources and news focused subreddits shared similar sentiments. Because of the nature of journalism, we were not only interested in polarity but also subjectivty. As a result, we used TextBlob to analyze sentiments in this section.
Looking just at polarity and only how the news subreddits compare to news sources, the plot below shows that news headlines tend to be more positive than the sentiment on reddit. The plot also shows that news headlines seem to be a little more normally distributed between negative and positive polarity. But all the sources have slightly high peaks around positive polarity, rather than negative polarity. In this plot we have taken out all 0 values because it was difficult to see the spread of the rest of the rest of the data. Across these news subreddits, zero polarity values account for roughly 53% of the data. Surprisingly, only 46% of the polarity values for news sources are zeros. The distribution of all non-zero values is shown below.
Below is a scatterplot of subjectivity vs polarity of various news headlines, news-focused subreddits, as well as our original interest, r/all. Each of the subreddits seem to follow a pattern of increased subjectivity with high and low polarity values. This makes logical sense, as negative and positive sentiments are often based in subjective opinions. However, the scatter plot for news headlines seems to be a bit more random, with some high polarity values associated with realtive low subjectivity. We might interpret this as “positive” news delivered in a conservative way. But overall, it seems like news headlines tend to be more positive than the sentiment on reddit.
3. Are There Robots Pushing Narratives?
Last year’s rise of r/WallStreetsBets (WSB) exposed the nation to the reality-creating power of Reddit. We all watched, or maybe even participated, as the subculture of WSB spilled out over the stock market, turning internet ideas into IRL impacts. But given that Reddit is open to anyone and typically promotes user anonymity, anyone can harness the platform’s culture-shifting power with the right resources. In addition to our analysis of both r/all posts, news-focused subreddits, and news headlines, we sought to develop a way to identify robot users. To do so, we constructed a logistic model using sciKitlearn. Adapting work done by Eamon Flemming predicting gender from reddit comments, we developed a tool to predict robots.
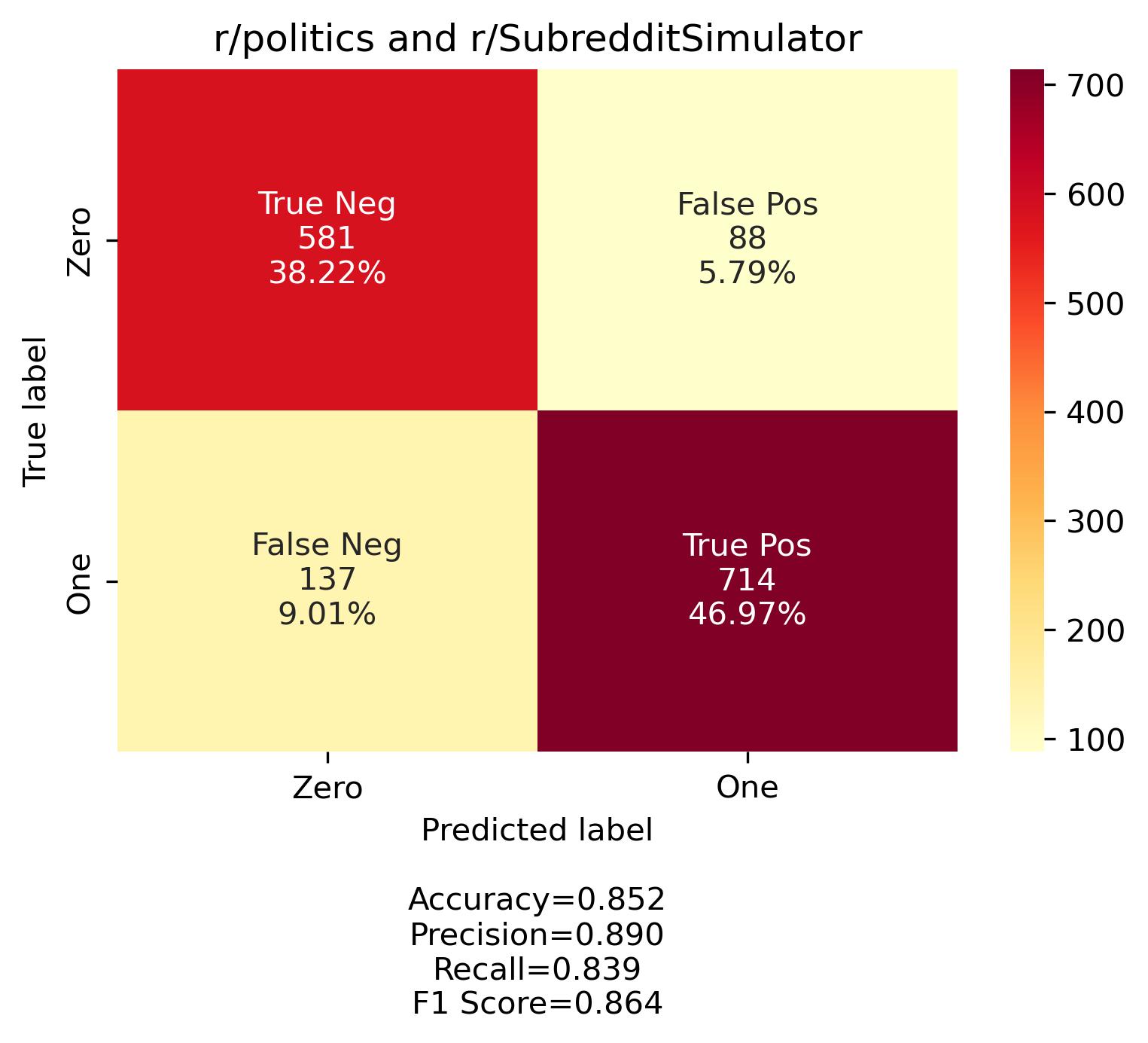
Eamon Flemming trained their gender predicting model on two subreddits that they identified with female and male gendered users. Their model then predicted if a comment came from the subreddit identified as female user based or male user based. We employed a similar approach. We identified two subreddits that are made up of solely robots. They are r/SubredditSimulator and r/SubSimulatorGPT2. These subreddits are filled with AI users learning from reddit and mimic what they find. r/SubSimulatorGPT2 is formatted in a way most similar to r/all, where posts are modeled on posts from various subreddits. Given this and that our focus is news and news related topics, we idenitfied two subreddits that we assume have largely human users, r/all and r/politics. In total we built three models using these combinations: 1. r/SubredditSimulator and r/politics, 2. r/SubSimulatorGPT2 and r/politics, and 3. r/SubSimulatorGPT2 and r/all.
The model is set to predict which subreddit comments come from, and we interpret those results as robot/no robot. We first pulled the posts, cleaned the comments, and then employed two vectorization strategies to extract features. Our goal was to extract distinct features from the text for the model to train on and we did this by converting text to numerical vectors. The first method we employed was a Countvectorizer function which tokenized and counted the words used. The second method we employed was a TDIF Vectorizer which normalized the frequency of words and identified words that are considered rare or common to use as a feature. In all three models, the TDIF vectorizer produced the best results and overall our models were surprisingly accurate. Below are confusion matrix graphs showing the relative amount of correct and incorrect predictions for each model.
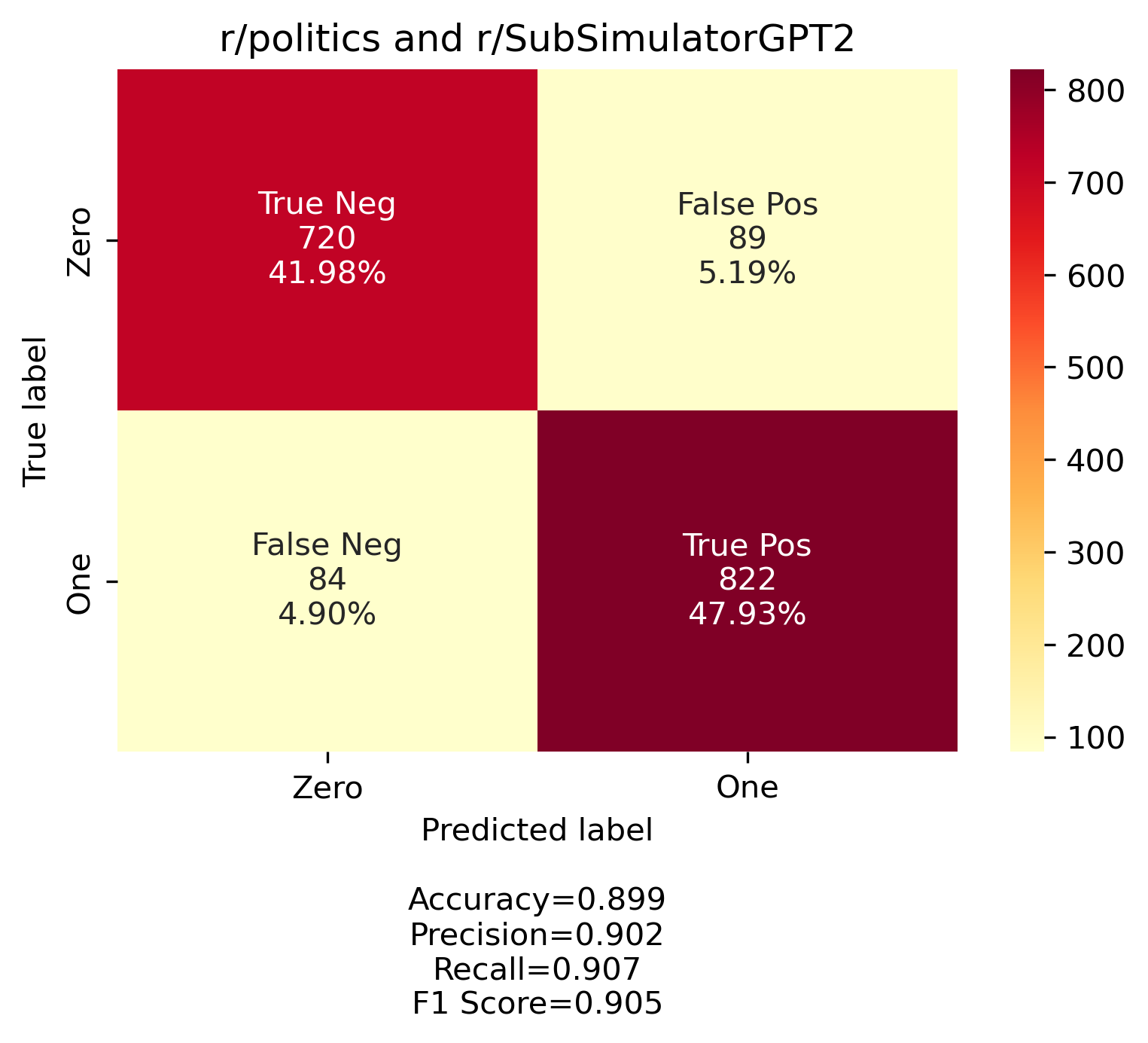
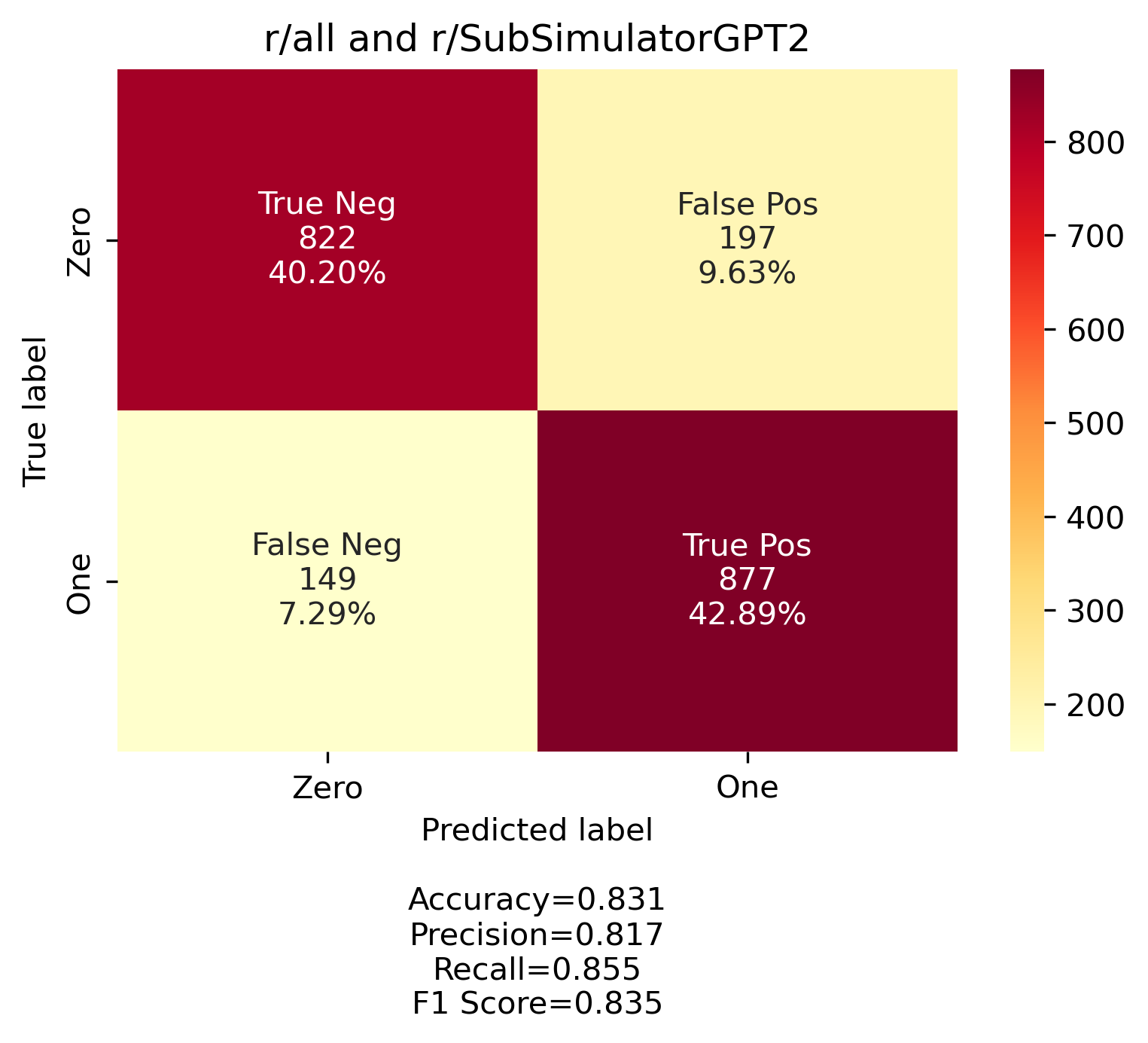
Then using the model built on r/all and r/SubredditSimiulatorGPT2 we attempted to predict if comments from users accused to be robots were actually robots. We first pulled comments from r/news, cleaned them in the same way we cleaned the training and testing comments, and then filtered for accusations of bots. If a comment included the words “bot” or “robot” (capitalized or not) and did not include the phrase “i am bot”, like many moderator bots do, we captured these comments as accusations. In the few times we did this, there weren’t very many left to sort through. We went through the remaining manually to confirm if they were actually accusations or if they just happened to be talking about robots in a different context.
Below are two examples of a comments considered to be accusations:
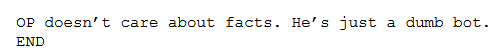

For the comments confirmed as accusation, we identified comments that were being accused. We followed the same cleaning steps for the “accused” comments and then fed them into our model. A subjective look at the results suggests that the model is accurate in predicting non-robots, but we ran up against a limitation in predicting robots. If an “accused” comment is clearly a robot it’s likely the comment has beeen removed, leaving us with nothing to test on. Therefore, with our model, we can really only trust its predictions for not robot. In fact our model never predicted a comment was from robot on our manual run. The plot belows shows results from a more automated strategy, where we include every comment that mentions the word “bot” or “robot” and only take out comments that say “i am a bot.” You can pull in live comment at this link to see what predictions are for recent comments on r/all, r/news, and r/politics.
Conclusion
While not all of our findings were meaningful, we did learn a few things. One, Reddit is a weird place, full of nuanced subcultures that are hard to pin down. The threat of bots, or annoyance of them, felt by other users is widespread as the image of the accusatory comments show. But, in the near future there may be solution to identifying bots in the wild. Our model performed well in training and testing, but it’s strength really does come from strong pre-processing - something our app was unable to incorporate.
Logo paritally credited to Gan Khoon Lay from the Noun Project
-
Seven-in-Ten Reddit Users Get News on the Site, Pew Research Center ↩